パソコンを活用した翻訳作業の手順書
翻訳を始めてから、かれこれ20年近くが経ちました。翻訳家に弟子入りしたこともなければ、関連する会社で働いたこともなく、自己流で試行錯誤を繰り返してきましたが、最近になって、やっと作業手順が固まってきた気がします(成長が止まったということかも知れません)。私の場合は、英語力が乏しいこともあり、パソコンやインターネットを最大限に活用して翻訳作業を行っています。参考になるかどうかは、かなり怪しいですが、備忘録を兼ねて、その手順を紹介したいと思います。
原文の入手
どこかから翻訳の仕事を貰えるような方には無縁の話だと思いますが、私のようにすべてを自前でやっている場合、まずやらなければならないことは原文テキストの入手です(その前に翻訳の対象を探すという手順も必要ですが、ここでは省きます)。
ウェブサイト上の文書を翻訳する場合は、そこからコピー&ペーストでテキストデータを取り出すことができます。PDFで公開されている場合も、同じようにテキストデータを取り出すことができます(テキストデータが含まれていない場合は、OCR処理が必要です)。
問題は、書籍の場合です。紙媒体をスキャンしてOCRで変換する手もあります。ただし、特に分量の多い書籍の場合、それには相当な労力を必要とします。また、英文の読み取り精度はかなり高いものの、どうしても誤認識の恐れが残ります。このため、Kindle版を併せて入手することが必須になります。
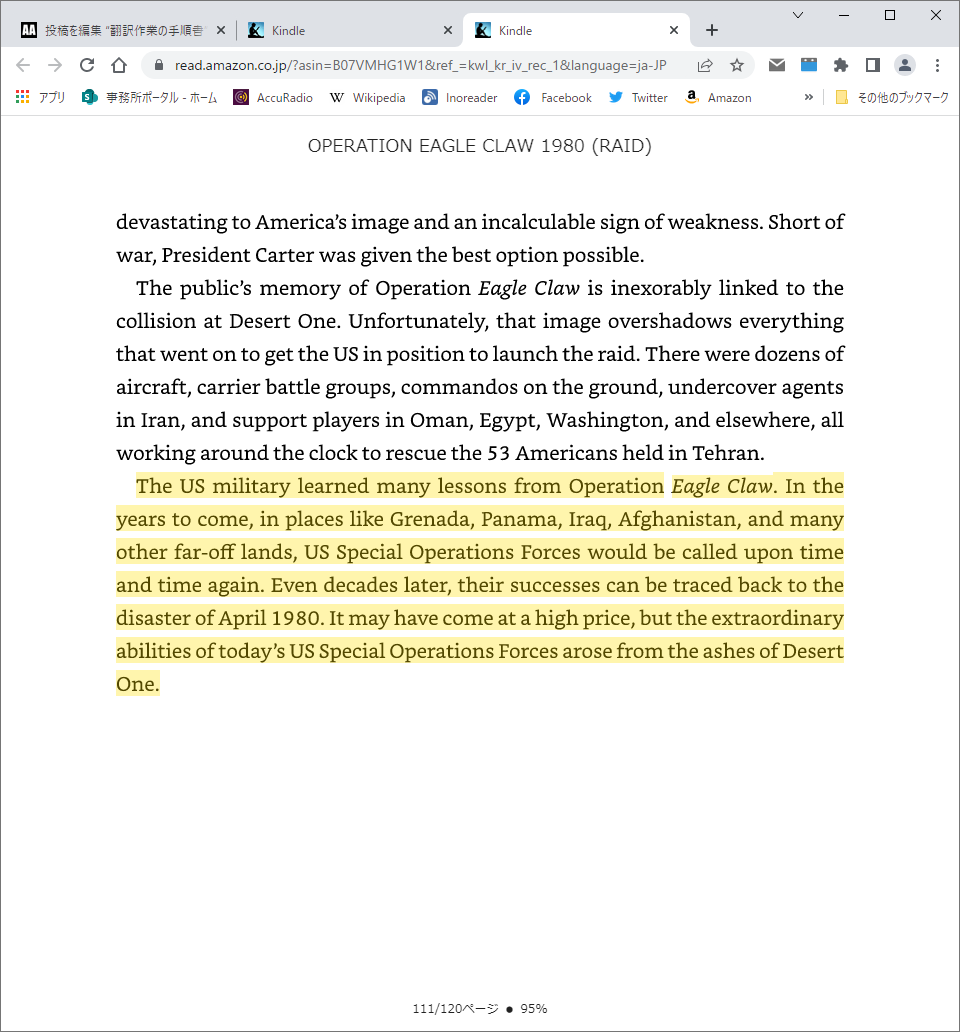
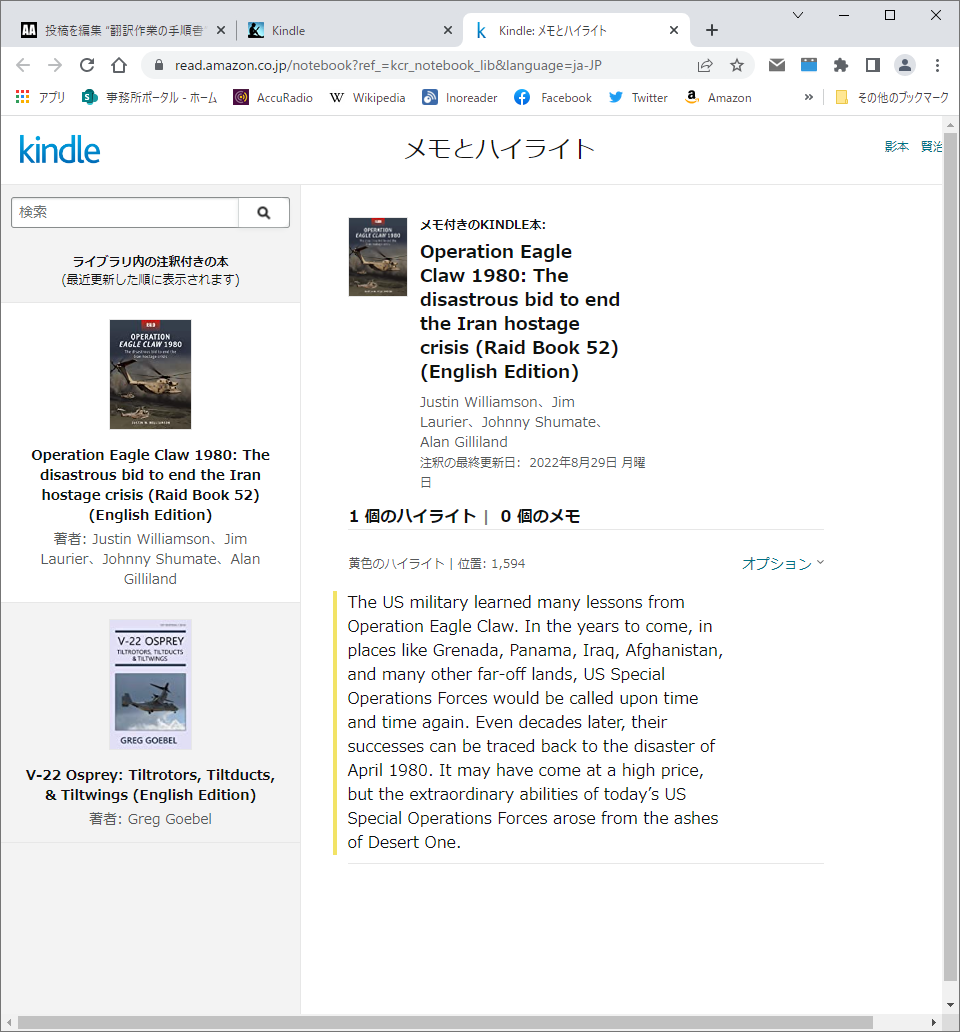
Kindle版の書籍ならば、「ハイライト」機能を使って、コピー&ペーストでテキストデータを取り出すことがきます。その方法については、こちらのサイトを参考にしてください。
段落をまたいでコピーすると、段落の切れ目が分からなくなるので、段落ごとに行うのがコツです。段落と段落の間には、空行を入れて置いた方がこの後の処理が簡単になります。ハイライト表示できる量に限界がありますので、章ごとくらいに区切って作業を行う必要があります。
原文ファイルの作成
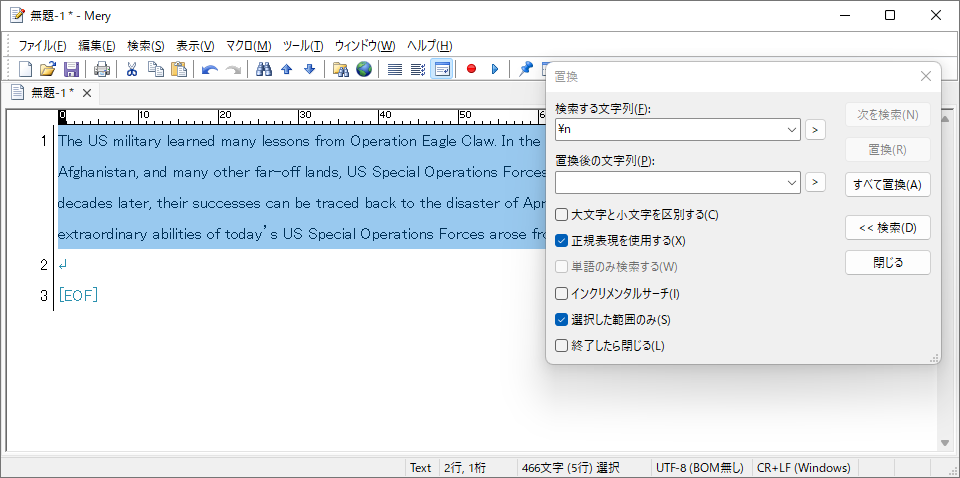
取り出したテキストデータには、翻訳には不要なタグや改行が含まれている場合がほとんどです。このため、テキストデータをエディターに張り付け、整形する必要があります。私の場合は、Meryを使っています。マークダウン記法を使った見出しが使えるところが気に入っています。
原文をコピーした際に入ってしまった不要なタグは、置換機能を使って削除します。不要な改行についても、同じく置換機能を使って、空白に置き換えます。正規表現を使用して「\n」を「 」(空白)に置き換えてやればOKです(以前は、文章全体を自動的に修正するWordのマクロを使用していましたが、こちらの方が簡単かつ正確です)。
正規表現については、こちらのサイトを参考にしてください。
翻訳メモリへの読み込み
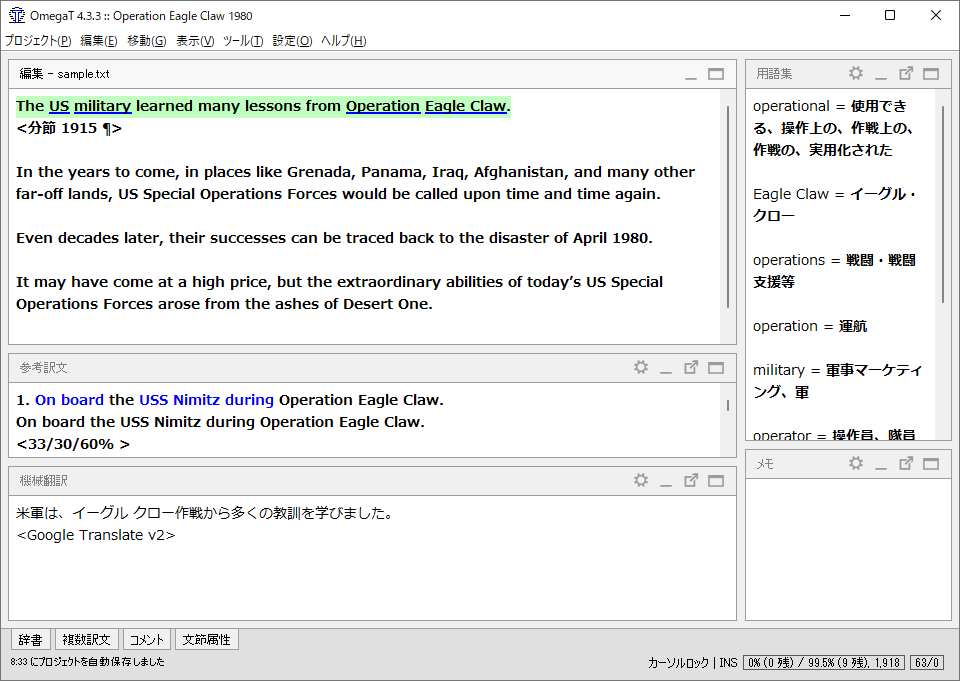
出来上がった原文ファイルを翻訳メモリに読み込ませます。私の場合は、OmegaTを使用しています。他のアプリケーションでも良いのですが、とにかく翻訳メモリを使わない手はありません。
なぜ、翻訳メモリを使うのかについては、こちらをご覧ください。 なぜ、OmegaTをお勧めするのかは、こちらをご覧ください。 OmegaTの使い方については、こちらのサイトを参考にしてください。

粗読み
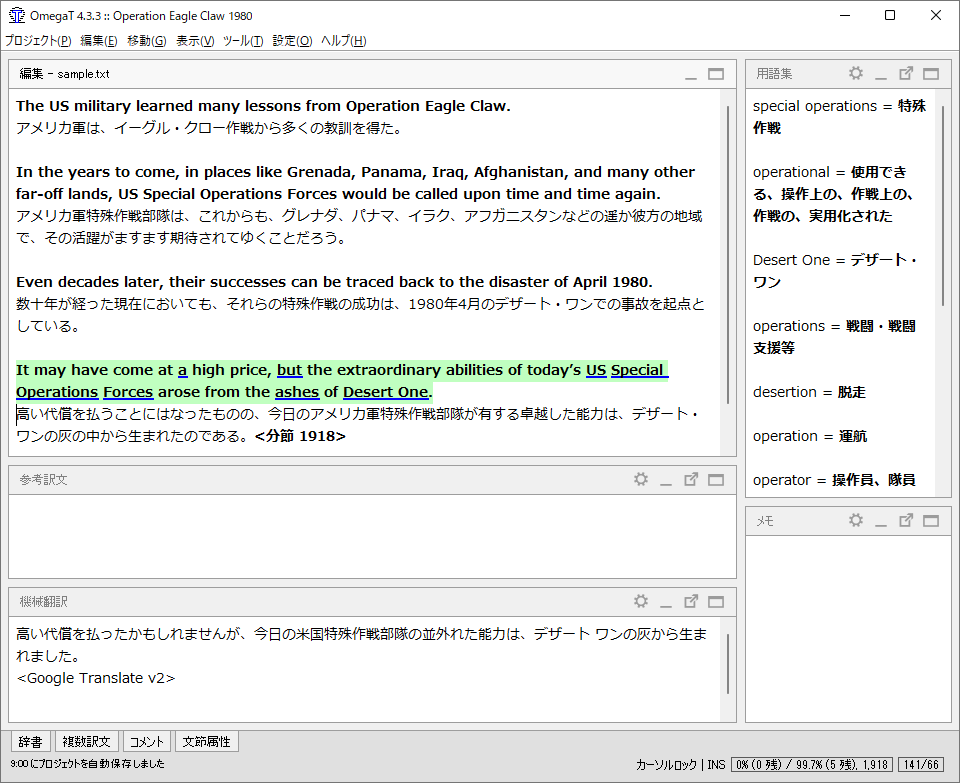
翻訳作業に取り掛かる前に、全体の内容を把握します。ここで使うのが、機械翻訳です。本当に英語のできる方には、「何言ってんだお前?」と言われそうですが、曲がりなりにも日本語で翻訳された文が表示されていると読むのがとても楽です。しかも、後で「下訳」をする際にも大いに参考になります。もちろん、人間が行う翻訳と比べると不適切な部分が多く、そのまま使えることは99%ありませんが、人間のように単語を読み間違えることがないので、助けられることもあります。
OmegaTの場合は、Ctrl+Mキーを押すと、機械翻訳ができます。私の場合は、Google Translateを使用しています。なお、翻訳させた文章は、誰からでも見られる状態になりますので、保全の必要なものには使えません。
最近注目を浴びている機械翻訳にTexTraがあります。こちらの方がGoogle Translateよりも自然な日本語になることが多いようです。ただし、人名などの固有名詞の訳語については、不適切な訳語を出力する場合がありますので注意が必要です(今後、改善されてゆくかも知れません)。
TexTraをOmegaTで用いる場合は、プラグインをインストールする必要があります。その要領については、こちらをお読みください。
用語集の作成
翻訳を始める際にまず行うべきことは、用語集を作ることです。この手順を飛ばして下訳にとりかかってしまうと、後で用語の統一に四苦八苦するはめになります。ちゃんとした翻訳業をされている方の場合は、依頼元から用語集が示されることもあるようですが、私のように自分で勝手に翻訳する者は、自分で作るしかありません。原文から頻出する重要語句を抜き出してもいいのですが、索引がついている場合は、それを活用するのが一番簡単で確実です。
ネットや参考書籍を調べながら、索引を翻訳し、その結果を用語集に追加してゆきます。OmegaTの場合は、対象となる英単語を選択した状態で右クリックすると用語集に追加できるようになっています。同じく選択した状態でCtrl+Fを押すと、全文検索ができますので、本文を含めた全ての訳語を統一してしまうのが良いと思います。
下訳
この段階で最も重要なのは、スピードです。とにかく、途中で挫折しないためには、最後まで翻訳を終わらせることに集中すべきです。「ドリーム・マシーン」を翻訳したときの最高速度は、約3,600ワード/日でした。ただし、私の場合は、その状態を2、3日も続けると、もう後が続きません。プロの翻訳家の方は、毎日12時間以上、翻訳を続けても何にも苦にならないという方もいるようですが、とても真似ができません。
翻訳する際には、あらかじめ作成した用語集はもちろんのこと、インターネットを総動員して適訳を探し出します。私の場合、辞書には英辞郎 on the Web、ネット検索にはGoogleを使用しています。英辞郎 on the Webは、とにかく語彙数が多いのが利点です。訳語には不適切なものが含まれている場合もあります(個人の感想です)が、それも含めて適訳を思いつくヒントになることが多いです。Googleは、英文を入力して、日本語のサイトのみを検索してやれば、他の方がどう訳しているかが分かります。画像や動画、地図なども検索できるところも便利です。Wikipediaも活用していますが、訳語にマニアックなものが多い(個人の感想です)ので注意が必要です。すでに翻訳・出版されている類書があれば、大変参考になることが多いです。
英辞郎をお勧めする理由は、こちらです。あらかじめ行った機械翻訳も、大いに活用しますが、そのまま使えることは本当にまれです(経験的には、100~200文節に1文節くらい)。機械翻訳に引きずられて誤訳をしてしまわないように十分な注意が必要です。
直訳が良いのか、意訳が良いのかも迷うところです。はじめの頃は、あえて直訳にこだわっていました。その方が抜けのない正確な翻訳ができるし、意訳にするのは次の本訳の段階でできると思ったからです。最近は、折角思いついた自然な日本語を忘れてしまわないように、躊躇せずに意訳してしまうようにしています。
単位の換算
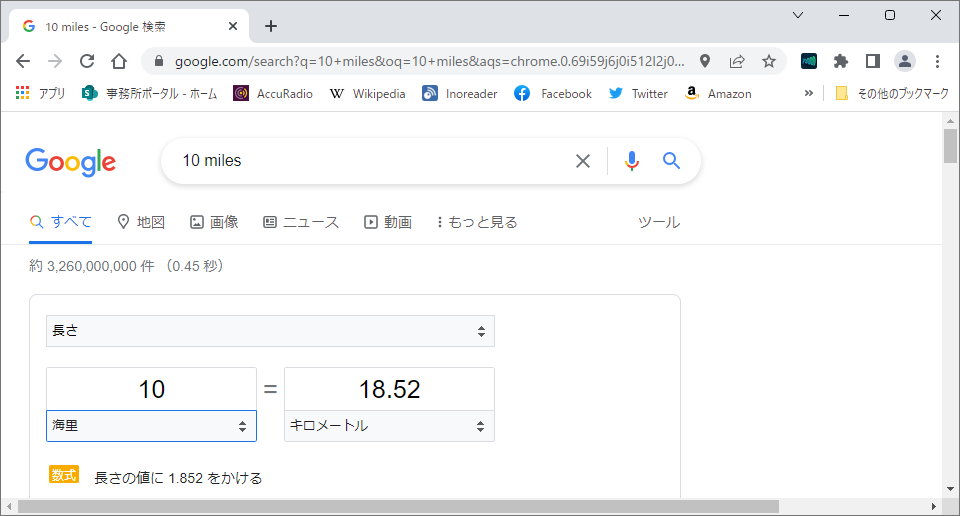
下訳がひととおり終わったならば、単位の換算を一挙に行います。逐次に行うと、同じ数値の翻訳結果が途中で変わってしまう可能性があるからです。単位の換算にも、Googleが役立ちます。
何桁で四捨五入するかも、結構、頭を悩ませる問題です。例えば、「about 10 miles」は、「約18.52キロメートル」、「約19キロメートル」、「約20キロメートル」などの翻訳が考えられます。私は、(何も根拠はありませんが)基本的に「約19キロメートル」と訳すようにしています。
陸マイルと海マイルのどちらなのかが不明確な場合もあります。地図上の位置関係が分かっている場合には、Google Mapでどちらなのかを判別します。
本訳
この段階で最も重要なのは、正確さです。下訳のときには、スピード重視のため「まあいいか」で済ませていたところもありますので、もう一度、GoogleやWikipedia、類書などをフルに活用してじっくりと調べ、誤訳がないようにします。どうしても疑問が解決しない場合には、出版元や原作者に質問する場合もあります。アメリカ軍の関係者は、レスポンス良く回答してくれることが多いです。一方、それ以外の民間雑誌社などからは、無視されることが少なくありません。また、書籍の著者については、出版社やエージェントを介した出版の調整が始まってからでないと、対応してくれないと思った方が良いでしょう。
併せて、もっと自然な訳にならないか、じっくりと検討します。訳語や訳文をGoogleを使って検索すると、よりしっくりくる同義語や例文が見つかる場合もあります。1つの文節を2つ以上に分割したり、逆に2つ以上の文節を1つにまとめたりもします。能動態を受動態に変えたり、あるいはその逆に変えたりすることも積極的に行っています(これは、以前、翻訳基本講座の先生から、「やめた方がよい」と指導されましたが、私のような機械を相手にすることの多い翻訳の場合は、避けられないと思っています)。直接話法を間接話法に変えてしまうことも、正確性を損なわない限り、躊躇せずに行っています。
私の場合は、納期のようなものがありませんので、できるだけ時間をかけてやっているつもりですが、それでも下訳の半分くらいの時間で終わることが多いです。プロの翻訳者の方は、下訳よりもはるかに長い時間を本訳にかけるようですが、そのレベルには達していません(下訳に時間がかかり過ぎているのだと思います)。
推敲
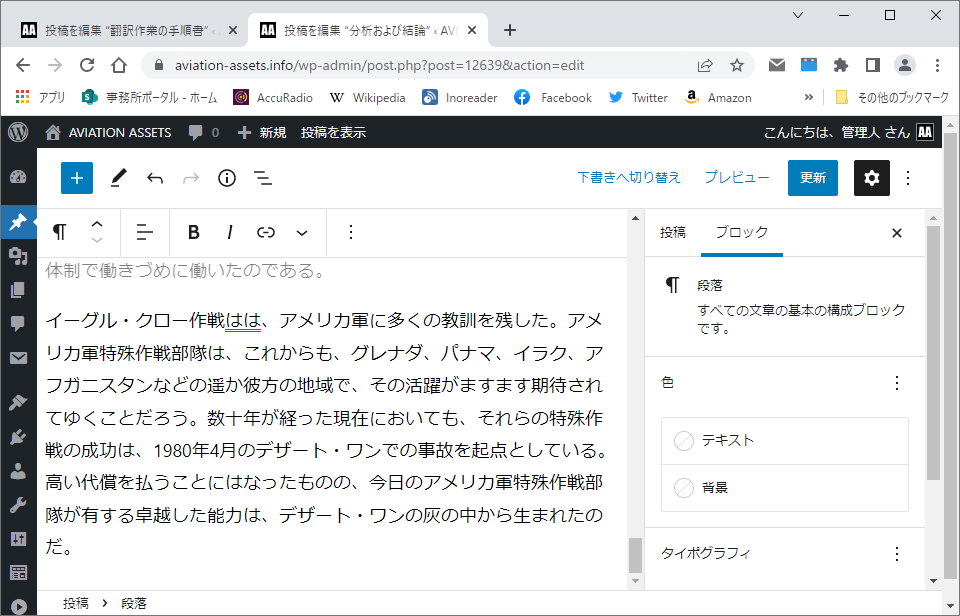
本訳が終わったら、訳文ファイルを生成してWordPressに流し込んでやります。私の場合、ほとんどの翻訳はウェブ上で公開することになりますし、雑誌や本で出版する場合も、事前に他の方に見ていただくことが多いからです。ブロックエディターにテキストをコピー&ペーストしてやるだけで、きちんと段落を認識して処理してくれます。
以前は、一旦、Wordやウェブ上の校正サイトに流し込んで校正することが多かったのですが、Chromeの拡張機能にMicrosoftエディターを設定しておけば、WordPress上でも自動的に校正を行ってくれますので、最近は使っていません。
この状態になると英文が見えなくなり、代わりに前後の段落との関係が見えるようになりますので、全体を見ながら必要な修正を加えてゆきます。
重大な誤訳を見つけた場合などは、一応、OmegaTの方も修正しますが、経験上、それが後で役に立つことはまれです。基本的には、後戻りせず、どんどん修正を加えていった方が効率的だと思います。
この段階までくると、自分の力では、問題点を見つけることは難しくなります。他の人に読んでもらって、気になるところを指摘してもらうのがとても役立ちます。英語のできる方でなくても、その分野に精通している方ならば、訳文を読んだだけで違和感があるものです。そういう部分は、たいていの場合翻訳に問題がありますので、もう一度調べなおします。まれに、原文そのものに誤りがある場合もあります。Amazonのレビューなどを読むと、そういったことを指摘するコメントが見つかることもありますので、参考にしています。
推敲が終わったら、図や写真を流し込んでやります。ブロックエディターのおかげで、図の配置などは簡単に設定することができます。出版社に原稿を提出する場合には、テキストを抜き出して提出します。
自分が翻訳を始めるまでは、翻訳なんて、そのうちコンピューターが自動的にやってくれる時代が来る、と思っていました。しかし、実際に始めてみると、クリエイティブなこの作業がコンピューターに完全に取って代わられることはない、と思うようになりました。
その一方で、インターネット、翻訳メモリ、機械翻訳、エディターなどを活用することで、より速く、簡単に、かつ正確に翻訳を行えるようになってきています。昔の翻訳者は、いったいどうやっていたのか、と思ってしまいます。この時代に生まれたことを感謝せずにいられません。
発行:Aviation Assets 2022年08月
アクセス回数:4,845
コメント投稿フォーム
5件のコメント
素晴らしいですね。システムやプログラムを使いこなせると効率的な仕事が可能になる好例です。
翻訳については,40年以上していますが,人の知恵や発想力には及ばないと思います。
私が,推敲する部分は,「遙か彼方の地域」を,「祖国(米国)から遠く離れた地域で」というと実感がわくと思います。
デザート・ワンの灰の中から生まれたは,推敲するのが最も面白い部分です。ashを灰と直訳するのか,「尊い犠牲」,「偉業」と意訳すると面白い表現になると思います。
ありがとうございます。「祖国(米国)から遠く離れた地域で」使わせて頂きます。「灰」の方は、文章全体を見ると、そのままの方が原作者の意図が伝わる気がしますので、そのままにさせて頂きます。
TexTraに関する記述を追加しました。
単位の換算に関する記述を追加しました。
類書に関する記述を追加しました。